📺 Original Video: OpenAI just dropped GPT-5.4 and WOW…. by Matthew Berman
📅 Duration: 16:27 · Published: March 6, 2026
TL;DR
- GPT-5.4 is OpenAI’s first true “everything model” that merges 5.2’s personality with Codex’s coding chops, finally catching up to Opus 4.6’s unified approach
- It dominates benchmarks: 75% on OS World computer use, 57.7% on SWEbench Pro, and 83% on GDP val (OpenAI’s knowledge work benchmark), beating both its predecessors and competitors
- You’re paying 43% more than 5.2 ($2.50 vs $1.75 per million input tokens), and the Pro tier jumped to $30 per million, but you get 1 million token context and serious efficiency gains
- The model crushes at computer use, browser automation, and building full apps from vague prompts, but has rough edges: terrible front-end taste, misses obvious context, and stops short in agentic workflows
- Industry consensus: this might be the best model on the planet right now, though Sam Altman already promised fixes for the quirks
OpenAI Finally Made Their Opus Killer
▶00:00 Berman got early access to GPT-5.4 and says we might actually have a new best model on the planet. The story here is familiar: OpenAI pulled the same move Anthropic did with Opus 4.6. Both companies are building models for real-world knowledge work, not just benchmarks. These are agent-first models.
▶00:40 Here’s why this matters. Opus 4.6 had it all: world knowledge, stellar coding, solid reasoning, and a personality you’d actually want to talk to. That last part matters more than people think, especially when you’re plugging a model into your daily workflow with something like OpenClaw.
▶01:13 OpenAI didn’t have that. You had GPT-5.2 for personality and creative writing, or you had Codex for coding. Pick one. You couldn’t have both. It was like choosing between a charming dinner guest and a contractor who actually shows up on time.
The “Have a Baby” Strategy
▶01:48 So OpenAI did something simple and brilliant: they told 5.2 and Codex to have a baby. That baby is GPT-5.4.
▶02:22 This is their new frontier flagship everything model. Good at coding. Has personality. Handles creative writing. Tool calling works. Agentic use cases actually work. You can plug it in as your main model in OpenClaw and it won’t embarrass you.
▶02:46 And they didn’t just merge capabilities, they made it faster and more token efficient. When Sonnet 4.6 came out, it was clearly built for knowledge workers. That’s exactly what 5.4 is now.
▶03:08 Think about the stuff you’d do with something like Claude for Work: reading PDFs, creating PowerPoints, web search, browser automation, computer use. GPT-5.4 can do all of these things well.
▶03:22 And here’s the final piece: 1 million tokens of context. The Claude family had this. OpenAI didn’t. Now they do. That’s huge.
The Benchmark War Continues
▶03:40 Two models dropped: 5.4 Thinking and 5.4 Pro. The benchmark chart tells a good story. OS World computer use: 75% for GPT-5.4 Thinking versus 74% for GPT-5.3 Codex and 72.7% for Opus 4.6.
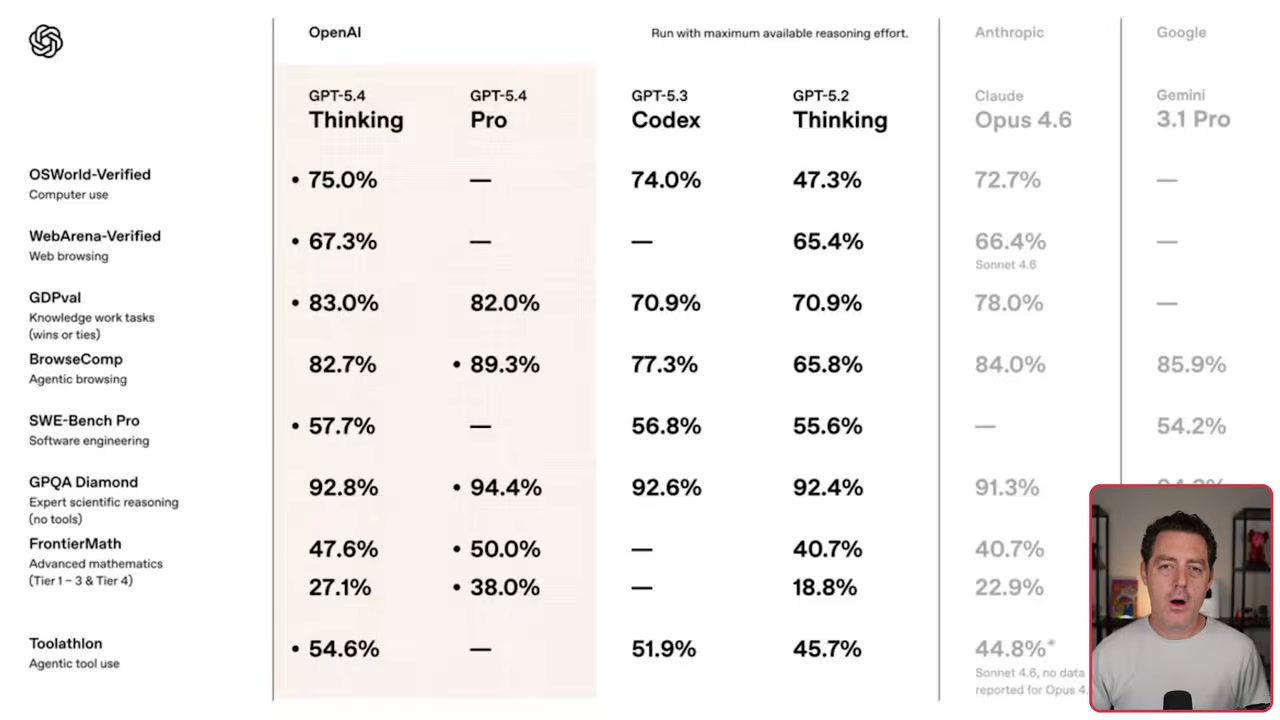
▶04:16 SWEbench Pro: 57.7% on Thinking, beating the Codex-specific model and Gemini 3.1 Pro’s 54.2%. Then there’s GDP val, OpenAI’s real-world knowledge work benchmark: 83% for GPT-5.4 Thinking. That’s 13 points higher than Codex, five points higher than Opus 4.6.
▶05:31 The computer use and vision capabilities are genuinely impressive. On the OS World benchmark, GPT-5.4 is way more efficient, hitting 75% with only 15 tool yields versus 5.2 struggling under 50% with 42 tool yields.
Computer Use Demos That Actually Impress
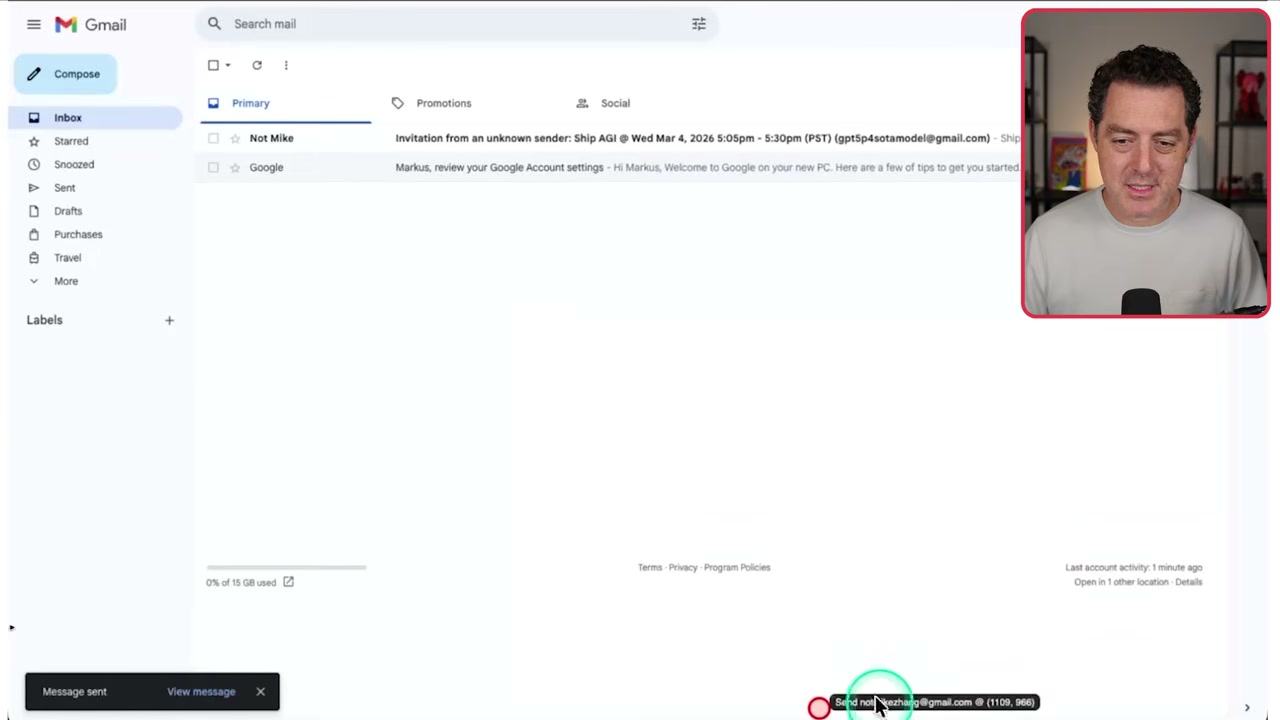
▶09:02 The Gmail demo is wild. It clicks, navigates, stars emails, labels them, creates calendar invites. Writes emails, sends them. Then there’s bulk data entry from JSON, running at real-time speed. That’s kind of insane.
▶10:05 OpenAI showed off a few things GPT-5.4 built. First: a theme park simulation game from a single vague prompt. You’ve got funds, guest tracking, happiness metrics, cleanliness, park rating. All of it just works. Next: a 2D 90s-style RPG with beautiful assets.
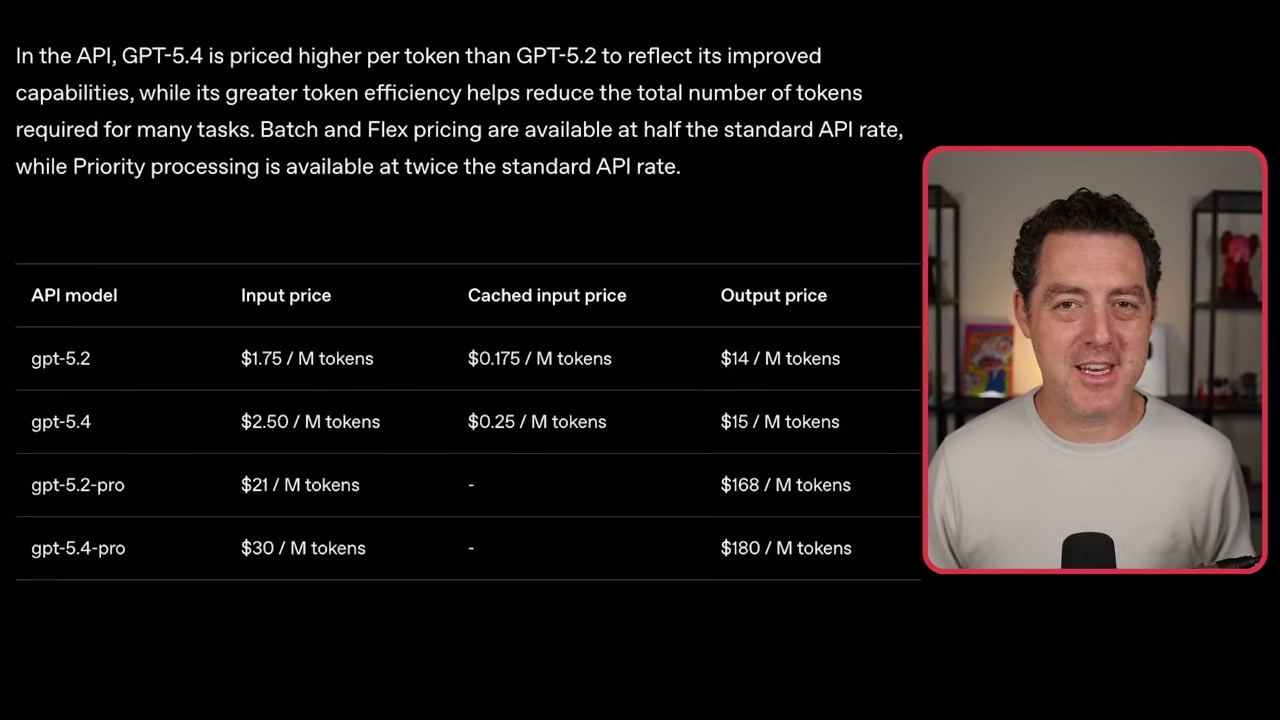
The Price You Pay for Progress
▶11:18 Let’s talk money. GPT-5.2 cost $1.75 per million input tokens. GPT-5.4? $2.50. Frontier intelligence is getting more expensive, not less. The Pro tier jumped from $21 to $30 per million input tokens. Output went from $14 to $15. Pro output: $180 per million versus $168.
▶12:10 You can use it as your primary model in OpenClaw, but fair warning: the way you prompt GPT-5.4 is different than Claude models. You’ll want to find the latest prompting guide for 5.4 and point OpenClaw at it.
The Pre-Training Revolution
▶12:54 We’re getting new models almost every week. Both Anthropic and OpenAI have completely figured out their pre-training cycle. These models are just baking in the oven, and every time they think they have enough progress, they ship.

▶13:34 Less than a year ago, OpenAI was not doing well on pre-training. GPT-4.5 was massive, slow, expensive. Now the entire 5.0 family is fantastic. That’s a serious turnaround.
Industry Takes: Mostly Love, Some Real Criticisms
▶14:08 Matt Schumer called it “best model on the planet by far.” He used to run Pro models, not anymore. Says 5.4 Thinking is sufficient for all use cases. Coding capabilities are “ridiculous, essentially flawless.” Though Berman thinks that’s an overstatement, and honestly, yeah.

▶14:47 Here are the actual problems: front-end taste is way behind Opus 4.6 and Gemini 3.1 Pro. It can miss obvious real-world context (like planning a trip and completely ignoring spring break). Within OpenClaw, it kept stopping short before finishing tasks. Sam Altman reposted feedback saying “we’re going to fix those immediately,” which is good because those are real issues.
▶15:25 Flavio Adamo had been testing it in early access. Million token context, number one on SWEbench. He had a big update planned that previous models couldn’t handle. GPT-5.4 one-shotted it.
▶15:51 Peter Steinberger, an OpenAI employee, says the coding jump is more in line with 5.0 to 5.1, but now it’s unified and smarter on everything else. Writes better docs, better general-purpose agent, more pleasant to use.
▶16:10 Berman’s going to test it in OpenClaw for vibes and personality. “I suspect it does” have the right personality. We’ll see.
We try hard to get the details right, but nobody’s perfect. Spot something off? Let us know