
📺 Original Video: This Tiny Model is Insane… (7m Parameters) by Matthew Berman
📅 Duration: 13:53 · Published: March 5, 2026
TL;DR
- A 7 million parameter model is beating Gemini 2.5 Pro, DeepSeek, and others at the hardest reasoning benchmarks
- Uses recursive reasoning instead of just predicting the next token like traditional LLMs
- Counter-intuitively, smaller networks with more recursion beats bigger networks (2 layers > 4 layers)
- Could run on your phone and might be the actual path to AGI
The Claim That Sounds Too Good to Be True
▶00:00 A 7 million parameter model is beating frontier models at the hardest reasoning benchmarks. Not close, actually beating them. Gemini 2.5 Pro, DeepSeek R1, Claude 3.7, all left in the dust by a model with less than 0.01% of their parameters.
▶00:29 The paper is called “Less is More: Recursive Reasoning with Tiny Networks” and there’s a single author from Samsung. TRM (Tiny Recursive Model) gets 45% test accuracy on ARC AGI 1 and 8% on ARC AGI 2. Those numbers sound small until you realize most frontier models can barely crack single digits on these benchmarks.
Why LLMs Suck at Reasoning
▶01:01 Here’s the problem: LLMs generate answers auto-regressively, meaning they’re just predicting the next token. One wrong token and the whole answer falls apart. There’s no actual reasoning happening.
▶01:32 To work around this, models like GPT-5 use chain of thought and test time compute, churning through tons of tokens to “think” before answering. It’s the new scaling law everyone’s excited about.
▶02:05 But chain of thought is expensive, needs high-quality reasoning data, and is brittle. The reasoning it generates might be wrong. Then there’s pass at K, where you generate K different responses and pick the best one. But again, the core issue remains: these models aren’t reasoning, they’re guessing.
▶02:56 The ARC Prize has been the litmus test. Six years after launch, we still haven’t hit human-level accuracy. Gemini 2.5 Pro with massive test time compute? 4.9% accuracy. Ouch.

The Predecessor: Hierarchical Reasoning Models
▶03:32 Recently, hierarchical reasoning models (HRM) showed promise on puzzle tasks. HRM had two key ideas: recursive hierarchical reasoning and deep supervision.
▶03:58 Recursive hierarchical reasoning means looping through two small networks multiple times. The authors even provided biological arguments about different temporal frequencies in brains.
▶05:44 Deep supervision is clever: solve hard problems in tiny steps, take notes at each step, and pass those notes to the next iteration. It’s like showing your work in math class, except the model is grading itself.
▶06:06 Deep supervision doubled accuracy from 19% to 39%. Recursive hierarchical reasoning only bumped it from 35.7% to 39%. So supervision was doing the heavy lifting.
TRM: Simpler, Smaller, Better
▶06:35 This is where TRM (Tiny Recursive Model) enters. It’s an improved, simplified approach using a much smaller network with only two layers.
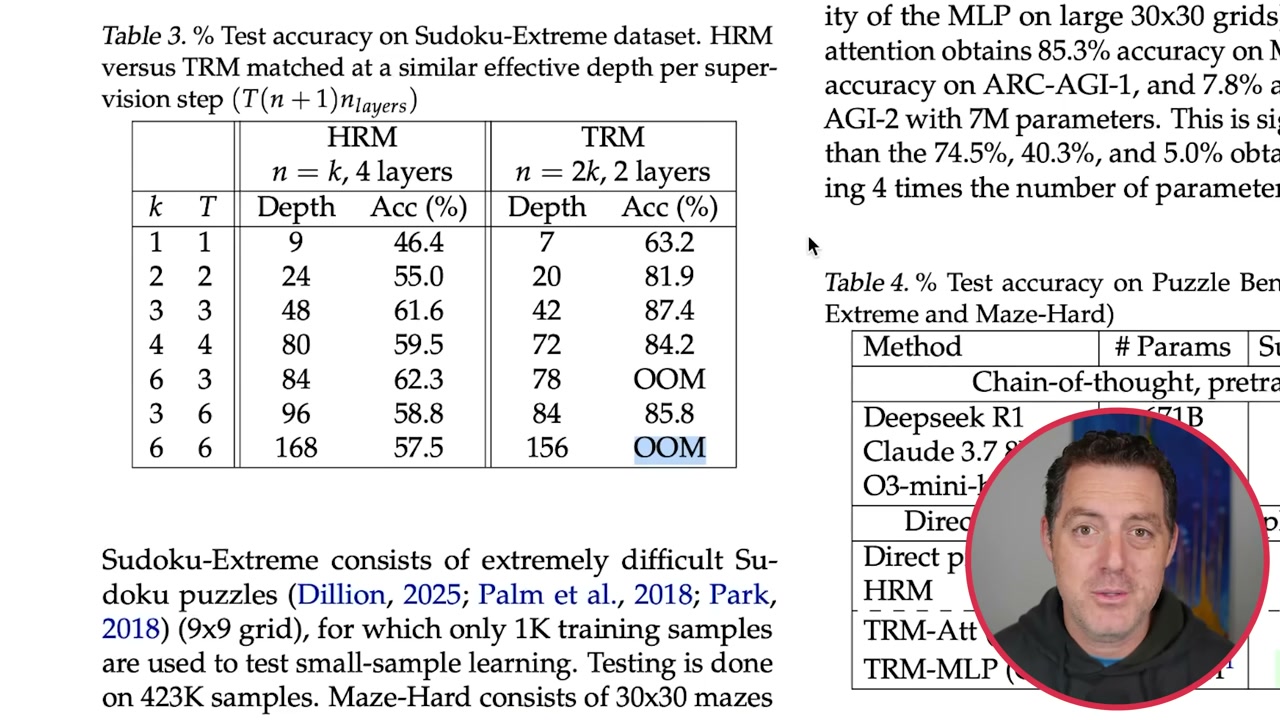
▶07:02 The improvements are wild. Sudoku Extreme: 55% to 87%. Maze (hard): 75% to 85%. ARC AGI 1: 40% to 45%. ARC AGI 2: 5% to 8%.

▶07:18 Here’s the analogy: imagine two brains, one thinking fast and one thinking slow, working in a loop together. Each pass refines the answer.
▶08:38 Unlike HRM, TRM doesn’t need complex mathematical theorems, hierarchies, or biological arguments. It generalizes better while using only one tiny network instead of two medium-sized ones.
The Beautiful Simplicity of It
▶10:04 The approach is elegant. The model keeps two memories: its current guess and the reasoning trace that got it there. Each recursion updates both. Like trying a Sudoku move, thinking about why it worked or didn’t, then adjusting.
▶10:26 Here’s the kicker: adding layers decreased generalization due to overfitting. Two layers instead of four maximized generalization. Smaller networks are actually better. Recursion gives you virtual depth without the parameter bloat.

The Results That Break Everything We Thought We Knew
▶11:28 When you increase depth with HRM, you see improvement then it plateaus. With TRM, you get much greater improvement with less depth.
▶12:04 On the ARC AGI benchmark, TRM scored 44.6% on ARC 1 and 7.8% on ARC 2. DeepSeek R1? Lower. Claude 3.7? Lower. Gemini 2.5 Pro? Lower. Only Grok 4 Thinking did better, but it’s over a trillion parameters versus 7 million.
▶12:46 In simplest terms: it thinks of an answer, thinks about that answer, critiques itself, revises, and repeats until it has the best possible answer. Self-correction built into the architecture.
▶13:03 Now we have a 7 million parameter model that’s incredibly good at reasoning. This might be the path to AGI, and it might be smaller than we ever thought. Imagine running this on your phone. Maybe recursion is the new scaling law.
We try hard to get the details right, but nobody’s perfect. Spot something off? Let us know